


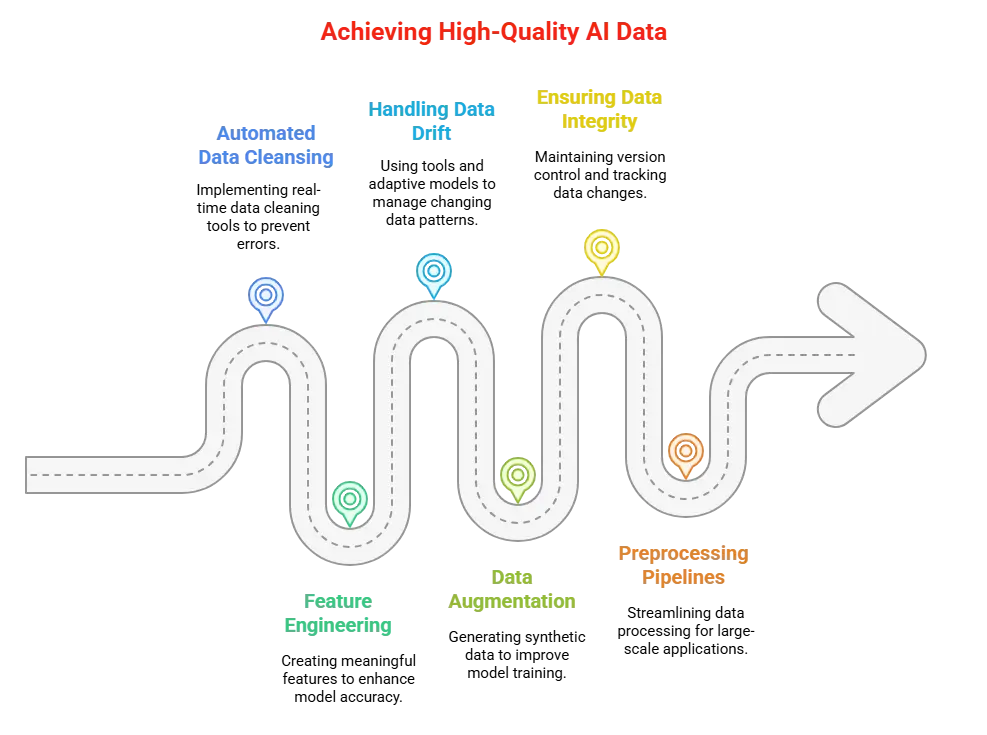



AI data modeling depends on one thing — data quality!
No matter how advanced your model is, bad data leads to bad predictions. Incomplete records, duplicates, and biased datasets cause serious problems.
These issues affect decision-making in healthcare, finance, manufacturing, and every AI-driven industry.
Solving data quality challenges is beyond just cleaning spreadsheets. It requires structured processes, automation, and the right tools.
This guide explains practical steps to improve data quality for AI data modeling.
 13 mins
13 mins









 Talk to Our
Consultants
Talk to Our
Consultants Chat with
Our Experts
Chat with
Our Experts Write us
an Email
Write us
an Email





